eResult team data engineering
Performance comparison Apache Kudu vs Databricks Delta

Apache Kudu (Cloudera) and Databricks Delta are two emerging open source storage layers, each of which implements ACID transaction, structured data model and aims to unifies streaming and batch data processing.
As official documentation states:
Apache Kudu provides a combination of fast inserts/updates and efficient columnar scans to enable multiple real-time analytic workloads across a single storage layer.
Kudu’s benefits include:
- Fast processing of OLAP workloads;
- Integration with MapReduce, Spark, Flume, and other Hadoop ecosystem components;
- Tight integration with Apache Impala, making it a good, mutable alternative to using HDFS with Apache Parquet;
- Strong but flexible consistency model, allowing you to choose consistency requirements on a per-request basis, including the option for strict serialized consistency;
- Strong performance for running sequential and random workloads simultaneously;
- Structured data model.
Databricks Delta Lake is an open source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs.
Specifically, Delta Lake offers:
- ACID transactions on Spark: Serializable isolation levels ensure that readers never see inconsistent data;
- Scalable metadata handling: Leverages Spark’s distributed processing power to handle all the metadata for petabyte-scale tables with billions of files at ease;
- Streaming and batch unification: A table in Delta Lake is a batch table as well as a streaming source and sink. Streaming data ingest, batch historic backfill, interactive queries all just work out of the box;
- Schema enforcement: Automatically handles schema variations to prevent insertion of bad records during ingestion;
- Time travel: Data versioning enables rollbacks, full historical audit trails, and reproducible machine learning experiments;
- Upserts and deletes: Supports merge, update and delete operations to enable complex use cases like change-data-capture, slowly-changing-dimension (SCD) operations, streaming upserts, and so on.
Reading between the lines you can see other similarities:
- each system implement methods to handle mutable data with the possibility to issue update, upsert and delete statements;
- each system is based on columnar storage format.
Based on all information above seem to be quite interesting to do a performance comparison.
Comparison environment
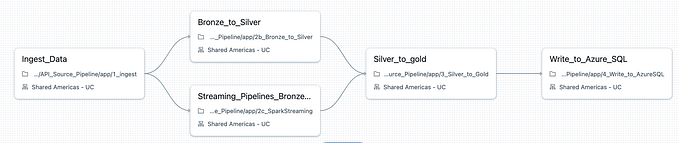
As I’m currently developing a customized version of our Omniaplace Big Data Pipeline with the aim of processing raw ECG digital signals, I decided to use our test environment to realized this comparison.
Speaking of data, our pipeline handles data in tracks, where each track contain 60 seconds of ECG signal digitized at 250Hz frequency.
Each track is treated by Spark python code to extract RR intervals and result data along with original signal are written to Kudu.
I have realized a variant of this pipeline that write to Delta lake, where parquet and delta log files are stored on the same HDFS file system as the Kudu tables.
This is the schema:

At OS level we have four VM’s, a single VM Cloudera CDH 5.13.0 with Kudu 1.5.0 and a Kubernetes cluster of three Ubuntu VM’s.
Spark cluster and Cloudera CDH execute in different hardware nodes connected by standard 1Gb network, so writing and reading require in each case (Kudu and Delta) network communication.
Our test code is written in Python and is run by a Spark cluster that live inside the Kubernetes cluster mentioned above (we won’t use the Spark module inside Cloudera distribution).
Spark cluster is run in client mode and code is operated in Jupyter notebook.
Our Omniaplace pipeline is used to test bulk insert while other tests are conducted directly from notebook.
Bulk insert
To test Bulk insert we start from empty Kudu tables and empty parquet folders, we load the system with 500 tracks the mean 10 minutes of 50 users data.
This means load the ECG table with 60*500*250=7.5M rows and the RR table with 60*500=30K rows.
Below the two code snippets used.
Kudu:
DF5_3.write.format('kudu') \
.option('kudu.master',"cloudera01.eresult.local:7051") \
.option('kudu.table',"impala::default.kudu_ecg_test8") \
.mode("append") \
.save()Delta:
DF5_3.write.format('delta') \
.mode("append") \
.save("hdfs://cloudera01/user/cloudera/geeks2/delta_ecg_test8")Here is the result (in seconds) of a trial of three test for each variant:

It’s important to take into account that the timing showed is not totally related to writing, there is also an 10–20% of transforming data from raw JSON objects that are ingested via MQTT, but this time is present equally in either pipeline versions.
After that we have to consider the network and the disk subsystems that can impose their performance limits.
Said that a fairly significant difference emerged and is in favor of Kudu solution.
Beyond this Kudu solution with his primary key constraint naturally avoids duplicates, thing that is difficult and very resource expensive to obtain in Delta.
Query with join
To test join speed I have sat up a query similar to the one below:
select
count(*)
from
(
select
a.*,
b.value
from
ecg as a
join
rr b
on ( b.project = a.project
and b.uuid = a.uuid
and b.track_id = a.track_id
and b.device_id = a.device_id
and b.ts = a.ts )
where
a.track_id like 'mqtt_ecg_%'
)
tmpWhere the join fields match with the primary key of the rr table.
Tables in Kudu and Delta are sharded over 50 partitions (that is our Kubernetes cluster parallelism) by hash(track_id), this is done in DDL for Kudu while it depend on how data is written by executors for Delta.
Query is executed against Kudu and Delta via:
- impala;
- spark sql.
This is the result in seconds:

Executing query from Spark involve Spark SQL execution engine and so I expected little to no difference from the two storage solution.
From Impala I expected some differences considering the deeper integration between Impala and Kudu:
Instead data show that differences exists in each of the scenarios, where spark sql engine seems to work better with Delta/Parquet format while Impala seems to work better with Kudu data.
While evaluating the results it’s necessar to take into account that in our architecture query from Impala are locally to the data while query from Spark are executed on other nodes and so network communication is required.
Single Select, Update, Delete
In Kudu single SELECT, UPDATE, DELETE with primary key are almost instantaneous.
Without primary key is the same as our test data has limited distinct values and for this reason the Kudu columnar format is very effective.
In Delta each single SELECT, UPDATE, DELETE require from 1 to 2 seconds and this is another point in favor of Kudu.
Bulk Upsert
This test is executed with Kudu ECG table and Delta ECG table loaded with 1500 tracks that means 30 minutes of 50 users load.
This means load the ECG table with 60*1500*250=22.5M rows and the RR table with 60*1500=90K rows.
We will upsert the ECG table with a dataframe containing 60*50*250=750K rows.
Kudu upsert in spark are possible only with scala, and so I tried to set up zeppelin notebook in kubernetes mode:
But the 0.9.0 release that implement this mode of operation is currently in preview2 and while is almost working it failed to load the required dependencies.
For this reason I decided to go ahead directly from spark-shell.
This is the code used.
Kudu:
import org.apache.kudu.client._
import org.apache.kudu.spark.kudu.KuduContext
import collection.JavaConverters._
val updatesDF = spark.read.format("delta").load("hdfs://cloudera01.eresult.local/user/cloudera/geeks2/delta_ecg_for_update")
val kuduContext = new KuduContext("cloudera01.eresult.local:7051", spark.sparkContext)
kuduContext.upsertRows(updatesDF, "impala::default.kudu_ecg_test8")Delta:
import io.delta.tables._
import org.apache.spark.sql.functions._
val updatesDF = spark.read.format("delta").load("hdfs://cloudera01.eresult.local/user/cloudera/geeks2/delta_ecg_for_update")
val deltaTable = spark.read.format("delta").load("hdfs://cloudera01.eresult.local/user/cloudera/geeks2/delta_ecg_test8")
DeltaTable.forPath(spark, "hdfs://cloudera01.eresult.local/user/cloudera/geeks2/delta_ecg_test8")
.as("old")
.merge(
updatesDF.as("new"),
"old.project = new.project AND old.uuid = new.uuid AND old.device_id = new.device_id AND old.track_id = new.track_id AND old.ts = new.ts")
.whenMatched
.updateExpr(
Map(
"ecg" -> "new.ecg",
"ts2" -> "new.ts2"))
.whenNotMatched
.insertExpr(
Map(
"project" -> "new.project",
"uuid" -> "new.uuid",
"device_id" -> "new.device_id",
"track_id" -> "new.track_id",
"ts" -> "new.ts",
"ecg" -> "new.ecg",
"ts2" -> "new.ts2"))
.execute()This is the result:

The performance gap here is very important.
Probably also in this case the primary key support in Kudu play a major role because upsert logic imply a direct record access.
Conclusion
Our test environment is a very small one, with limited data parallelism and a data size that can easily fit in memory.
For this reason this environment does not represent any real world scenario.
Said that in this environment Kudu demonstrated to work better in the majority of our test:
- faster bulk insert;
- faster join in combination with Impala;
- faster single select, update and delete;
- faster upsert.
This seems to depend on the presence of the concept of primary key that lack in the Delta Lake paradigm.